Machine learning predicts the future based on training data collected in the past. Machine unlearning removes training data from those models.
Existing papers about machine unlearning are written from the perspective of those with access to a model - machine learning engineers at a tech company, for example - who have received requests to remove training data from a machine learning system.
Retraining a model is computationally expensive. A machine learning engineer can attempt to remedy the problem by removing the problematic data from the database containing training data, but without retraining, the model's predictions still rely on the problematic data. This is the problem machine unlearning papers aim to solve.
I am interested in machine unlearning from a privacy standpoint. What if I want to remove pictures of my face from a facial recognition model? What can I do?
Machine unlearning algorithms attempt to approximate the effect of retraining the model from scratch.
Some algorithms, like SISA, actually modify the process of retraining the model. Other algorithms, like the projective residual update, rely on changing the model's weights but do not require retraining.
Models cannot identify patterns in unlearned data. Guo et al. provide two technical frameworks for understanding machine unlearning:
The notion of certified removal is a technical guarantee that a model from which data has been removed looks the same as a model that was never trained on that data. Additionally, the accuracy of the model from which data has been removed is identical to the model from which data was never removed.
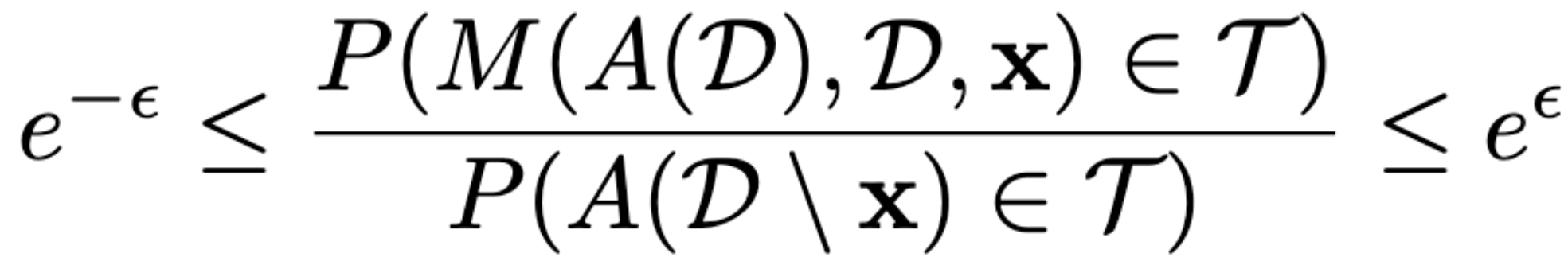
P stands for probability.
M is the data removal mechanism.
A stands for learning algorithm.
D stands for the hypothetical dataset which never observed the removed data.
x stands for the input to test the model.
e stands for the difference between the model trained on the dataset with data removed and the model trained on the dataset that never contained that data.
T stands for the set of all models in the hypothesis space H.
The episilon (the little e) is a measure of the divergence between the model from which data was removed and the model which never saw data. It is greater than zero (unless retraining from scratch).
We are measuring the probability of a model being able to tell the difference between a dataset from which data has been removed and a dataset which never saw that data. We measure this probability using input data.
In relaxed certified removal, the accuracy of the model from which data is removed is allowed to drop - but we don't want the accuracy to drop significantly.
I wonder whether I am the first person to consider combining machine unlearning with data poisoning. I have read quite a few machine unlearning papers without running into this concept.
Machine unlearning papers like that of Guo and Smart help us find the ideal model parameters for a model from which we want to remove data. These papers assume we have access to the model.
I wonder whether a data poisoning attack could allow one to generate training data that push model parameters to the desired state.
Essentially, it seems that this could be formulated as bilevel optimization - machine unlearning solves the outer optimization problem and a data poisoning attack would need to solve the inner optimization problem.
This was posted to IndieNews.